F1 Dominance Predictor
Fall 2024
Tools:

This project analyzes Formula 1 race data to predict team performance and their scored point in every Grand Prix based on historical race results,
lap times, and qualifying performances. Using data from the OpenF1 API
, we built a pipeline to collect, clean, and process multiple datasets, including driver stats, session data,
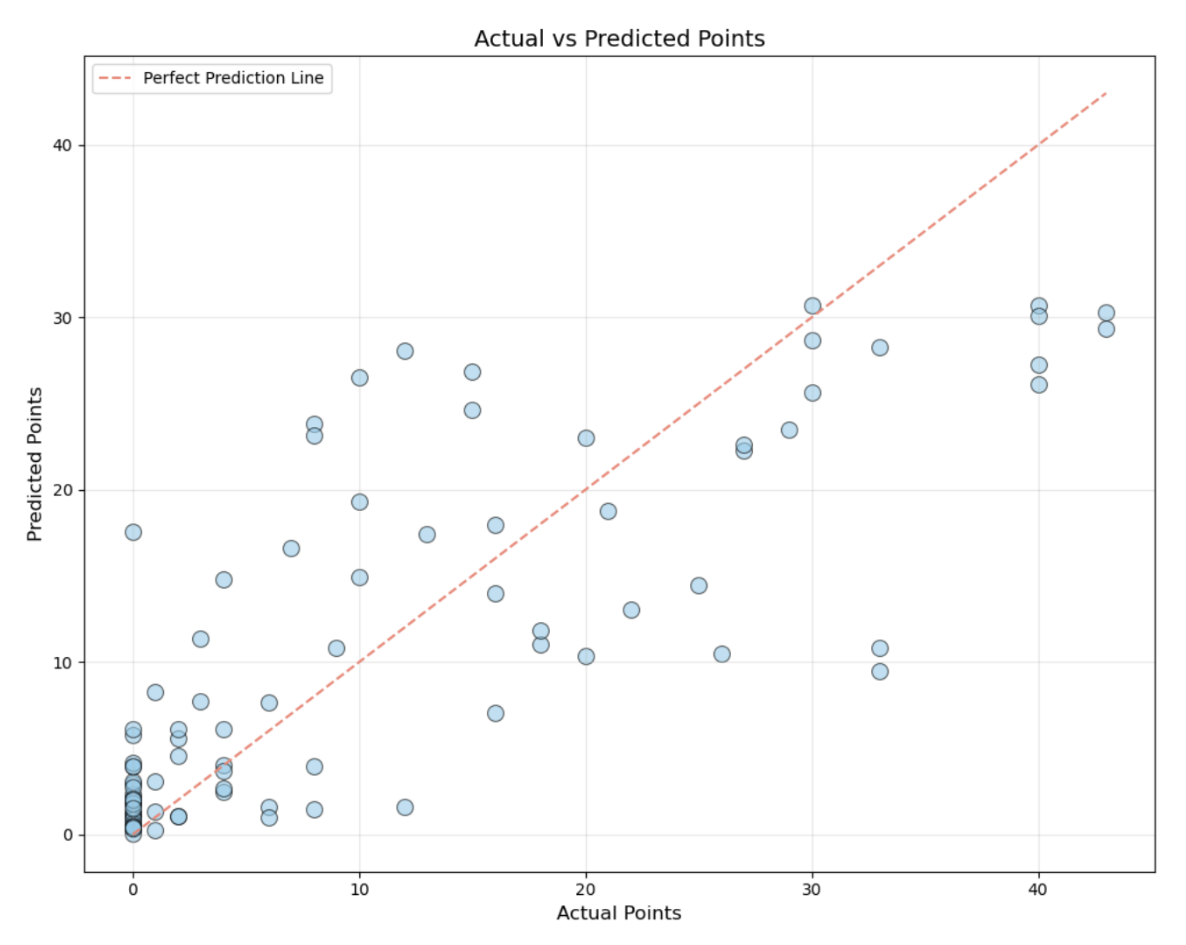
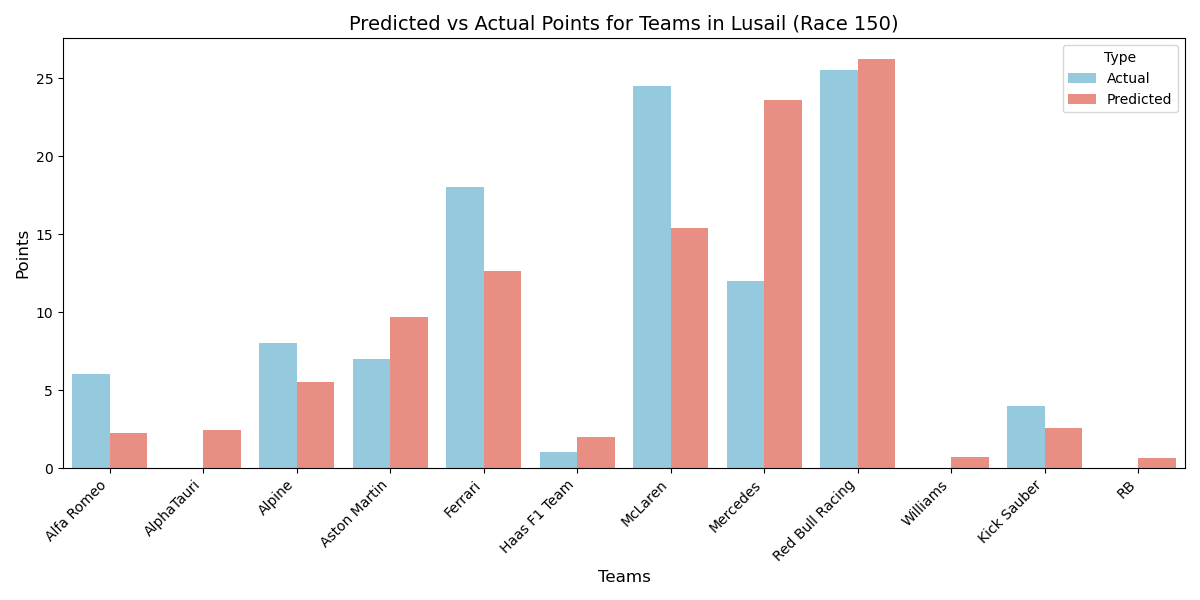
and race positions. After exploring various models, we selected a Random Forest Regressor, achieving a 64.41% validation
score in predicting total points earned by teams per race. Key challenges included limited historical data and approximating the official points system.
I did this project with one of my friends. My contributions included implementing a data pipeline to retrieve and process data
from the OpenF1 API, cleaning and filtering datasets using Pandas, handling data quality issues, and
applying feature engineering to optimize machine learning models. I also implemented and evaluated various models,
including KNN, Random Forest, and Linear Regression using Scikit-learn.This project showcases my experience in
data-driven decision-making and machine learning.